Welcome

Welcome to Apache Spark APIs for Data Processing, a self-paced, interactive course developed by CERN IT. This course offers a practical introduction to Spark’s powerful architecture and essential capabilities, combining theoretical insights with engaging demonstrations and hands-on exercises.
- Comprehensive API Coverage: Dive into Spark DataFrames, SQL queries, real-time Streaming, and Machine Learning to harness Spark's full potential.
- Interactive Hands-On Tutorials: Build practical experience with guided exercises in Python using Jupyter notebooks.
- Real-World Deployments: Explore how you can deploy Apache Spark at scale and see examples from CERN's accelerator logging systems, IT infrastructure monitoring, and physics research.
By course end, you will be equipped to confidently apply Apache Spark to large-scale data processing scenarios.
Accompanying Notebooks
- Download Notebooks: Access all materials on the Spark Training GitHub Repository.
- Run the Notebooks:
- Explore the SWAN Gallery and watch the intro video for more details.
 CERN SWAN
CERN SWAN
 Colab
Colab
 Binder
Binder
Course Lectures & Tutorials
- Introduction & Objectives:
- Session 1: Apache Spark Fundamentals
- Session 2: Spark DataFrames & SQL
-
Session 3: Data Platform, Streaming & Machine Learning
-
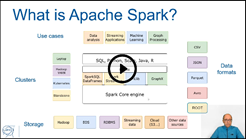
Lecture: "Spark as a Data Platform" –
Slides –
Video
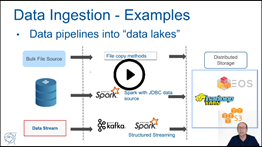
-
Lecture: "Spark Streaming" –
Slides –
Video

-
Lecture: "Spark & Machine Learning" –
Slides –
Video

- Notebooks:
- Demo: Read Oracle Tables Using Spark JDBC
- Note: Understanding Spark with Parquet
-
Lecture: "Spark as a Data Platform" –
Slides –
Video
- Session 4: Scaling Out Spark Jobs



Bonus Material
- Monitor Spark Execution: Slides – Video
-
Spark Performance Lab:
- TPCDS_PySpark – Benchmark workload generator.
- SparkMeasure – Metrics collection tool.
- Spark-Dashboard – Real-time dashboards.
- Spark as a Library: Explore examples in Scala and Python: Code Repository – Video Demo
- Next Steps: Dive deeper with Reading Materials & References and explore additional Spark Notes.
- Offline Materials: Download the complete course package: slides.zip, github_repo.zip, videos.zip or watch on YouTube.
Credits
Author & Contact: Luca.Canali@cern.ch
Presented by: CERN-IT Data Analytics Services
Contributors: R. Castellotti, P. Kothuri
License: CC BY-SA 4.0
Published: November 2022 | Last modified: March 2025